Hey there, tech wizards! Tim Tech Insight is here to spill the beans on an awesome tech trick — running those big, bad Large Language Models (LLMs) right from your own Mac or Windows machine, courtesy of LM Studio!
Before we dive into this tech-tastic adventure, remember that when you click those links on our site, you’re helping us out big time. We may even earn some affiliate commission mojo. Check out the details if you’re curious!
So, what’s the deal with LLMs like ChatGPT, Google Bard, and Bing Chat? Well, they usually party in the cloud, which means they’re hogging someone else’s computer. And trust me, that ain’t cheap — just look at ChatGPT’s premium option. But, hold onto your tech hats, ’cause LM Studio is here to change the game!
Setting up LM Studio on your trusty Mac or Windows machine is a piece of cake, and it’s the same delicious recipe for both. Sorry, Linux peeps, we’re not whipping that up today.
What’s Cookin’ in LM Studio
To get started, you’ll need a few ingredients:
- An Apple Silicon Mac (M1/M2/M3) with macOS 13.6 or newer
- A Windows or Linux PC with AVX2-supporting processor (the newer, the better)
- A tasty 16GB+ of RAM (for Mac folks), or 6GB+ of VRAM (for the PC crew)
- NVIDIA or AMD GPUs are in the mix
- A zippy internet connection for model downloads
If you’ve got this tech buffet going on, you’re ready to rock. Personally, I’m rollin’ with an RTX 4090 OC water-cooled packing 16GB of VRAM — one of the meanest graphics cards around, and boy, does it make text magic happen fast!
Step 1: Download and Fire Up LM Studio
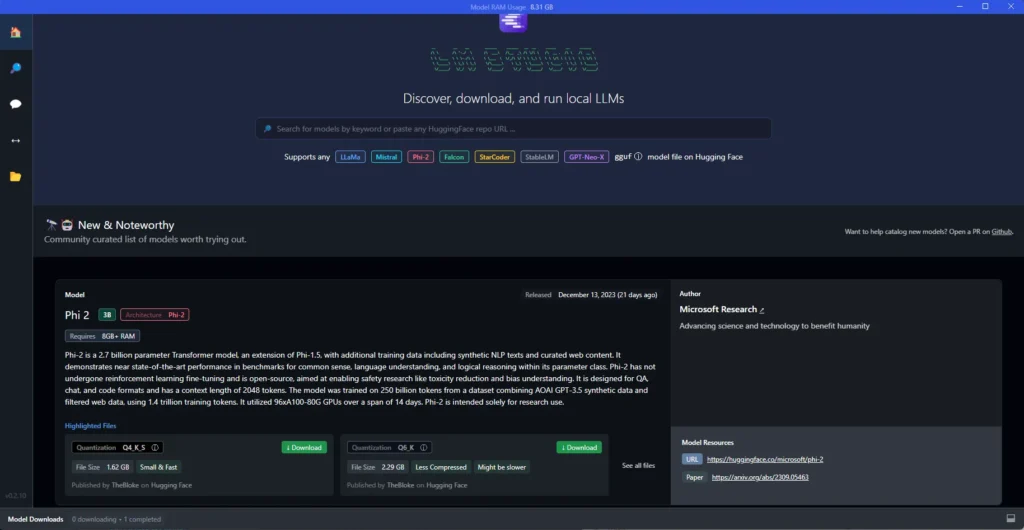
First things first, get yourself LM Studio from their fancy website for your chosen platform. It’s around 400MB, so for your download journey, you might want to take a coffee break’s worth of time, depending on your internet hustle. Once it’s on your machine, just give it a click, and voila, you’ll see a screen like the one above.
Step 2: Pick Your Model, Like a Tech DJ
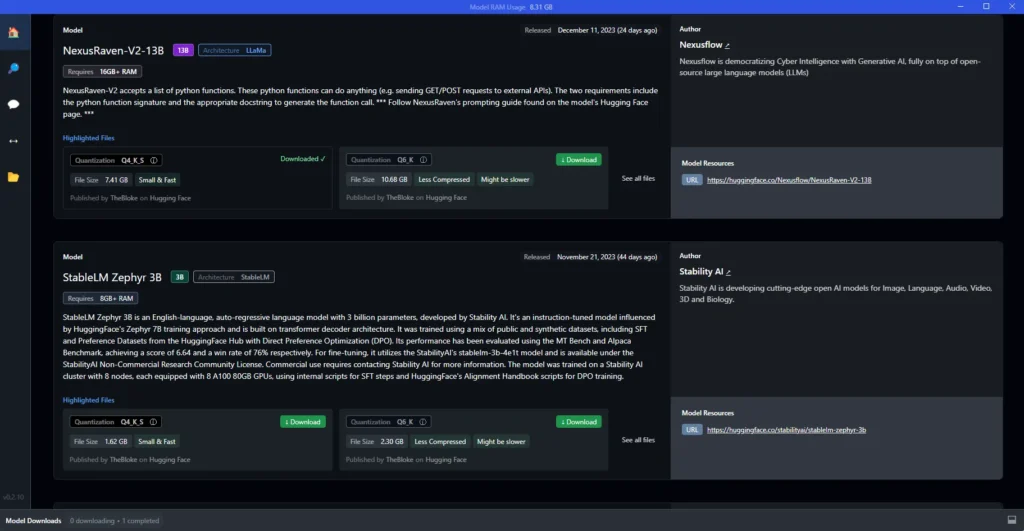
Now comes the fun part — choosing your LLM model! Click that magnifying glass icon and explore your options. These models are big boys, several gigabytes in size, so they might take a snack break during download. I currently roll with StableLM Zephyr-3B; it’s a compact, LLM-friendly choice. But hey, there’s a whole LLM party going on — take your time, browse, and see which one tickles your tech fancy. Zephyr’s my wingman; it’s trained as an assistant by the Stability AI team. Once you pick one, follow these steps:
- Let it finish downloading.
- Click the Speech Bubble on the left.
- At the top, choose your model.
- Give it a second to wake up.
Step 3: Tech Talkin’ Time!
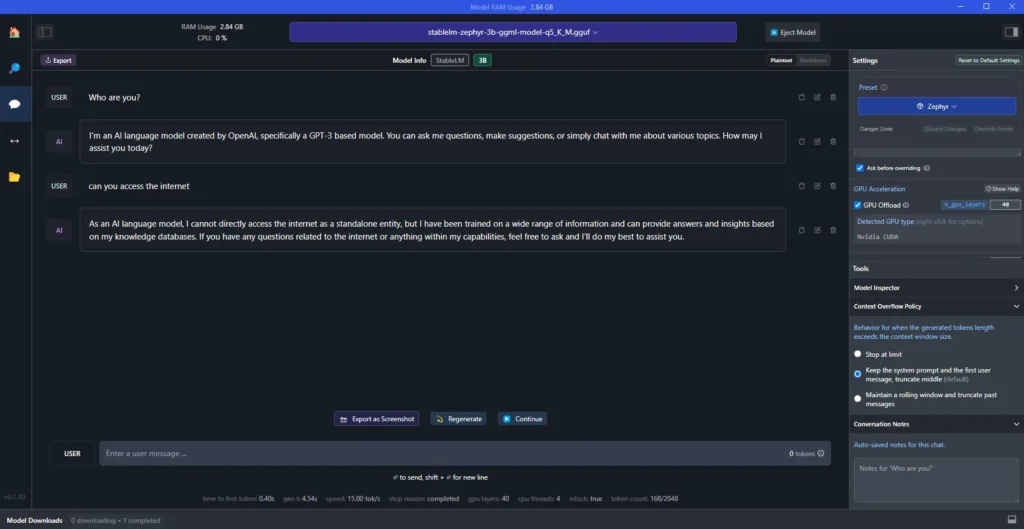
Now that you have an LLM ready to chat on your machine? To enhance those responses, you might consider a little GPU acceleration — think of it as the hot sauce of computing, optional but with a zesty kick. For my setup, I go with LM Studio on my water-cooled dual A6000s, packing 80 GPU layers. But if you’re using an RTX, begin cautiously at 5 layers. Increase gradually and if LM Studio crashes, that’s your cue — those settings are too hot to handle. Dial it back to the last stable point. This method is a great way to optimize performance but remember, it’s about finding that sweet spot without overcooking your system!
Why Go Local with Your LLM?
Now, you might wonder, why bother with local LLMs? Well, here’s the scoop. Privacy, my tech-savvy friends! LLMs can handle some seriously confidential stuff, and you might want to ask them about top-secret code (like debugging top-secret). Cloud-based LLMs? Nah, not for that gig!
And that’s just the tip of the iceberg. Sometimes, these LLMs are fine-tuned for specific tech adventures that Bard, ChatGPT, and Bing Chat can’t touch. Zephyr, my trusty sidekick, is an expert virtual assistant — it’s in a league of its own.
So, why wait? Dive into LM Studio, and let’s get that local LLM party started. Running your own LLM has never been this tech-tastic, my friends!